LLM Autocomplete Setup
In this post, I would like to share how I made my own setup of a self-hosted LLM for VSCodium.
It should work with other IDEs as well.
I am not a fan of fancy development environments, simply because I am not a developer.
I switch regularly between different IDEs and languages. For instance, I really like VSCodium for my own big projects, which I can upload to GitHub.
For smaller tasks, I prefer Sublime Text. Sometimes, I use Vim for quick tasks. Recently, I got a crazy idea about setting up autocomplete for Vim.
Perhaps I’ll do it one day, along with setting up my work machine.
Still, I do not want to be at a disadvantage compared to other developers when building big projects. Using LLMs gives them a reasonable speed boost in programming and simplifies coding overall.
Thus, I decided to set up LLM autocomplete as well, but in a way that suits me.
Now, let’s set up some goals:
- I want to have autocomplete for all languages (Python, JavaScript, TypeScript, C++, Java, etc.).
- I want it to be free, private, and open-source.
- I want it to be fast.
- It should be completely under my control and customizable.
- Preferably, I would like to have a built-in chat with the LLM to ask it questions related to the code.
- It must work without an Internet connection.
However, let’s keep in mind that the performance and quality of suggestions from our local 8B models will not be the same as those from big models like ChatGPT.
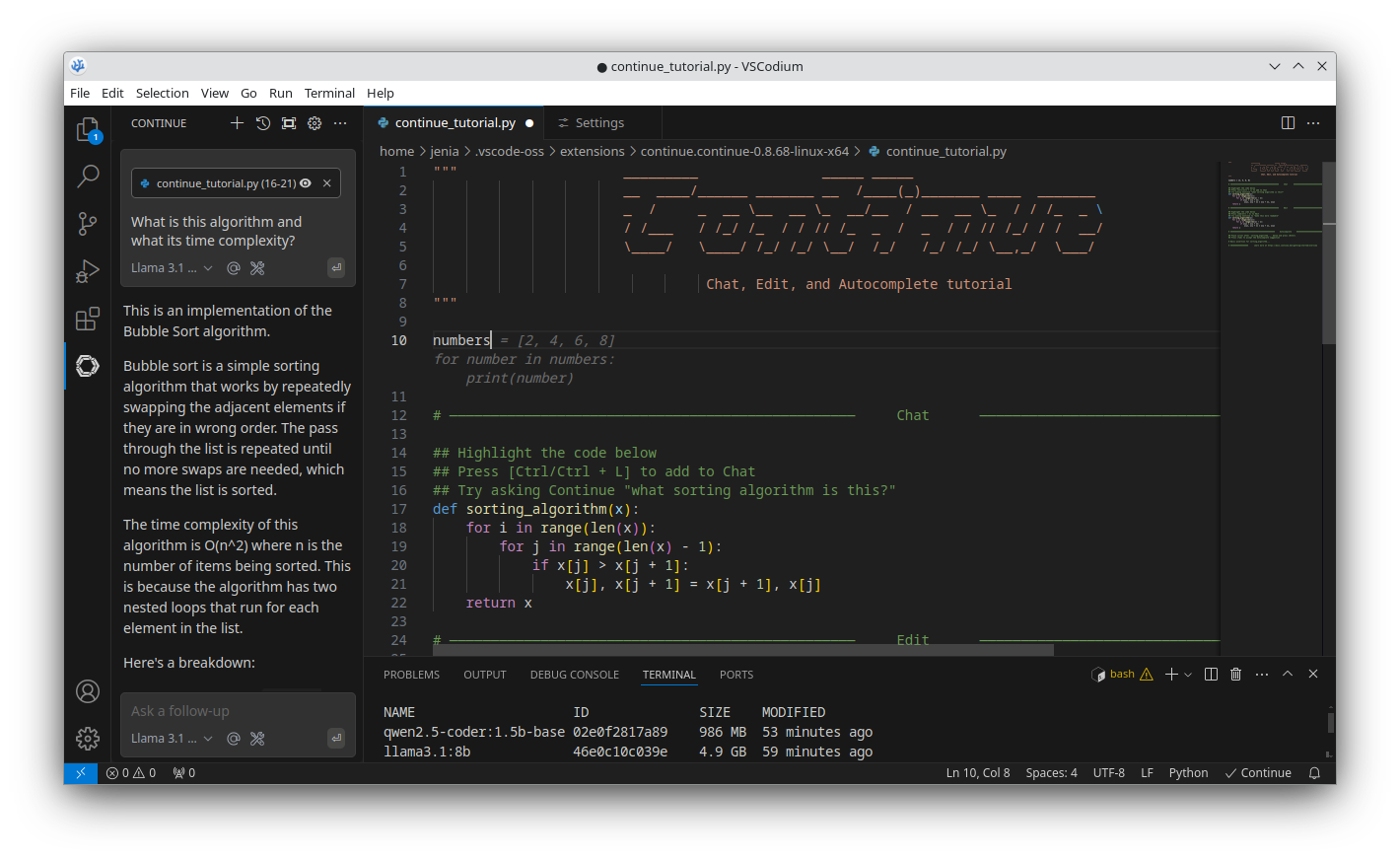
How Will It Work?
I already had some experience with Ollama, so I had it installed. You can start it with ollama serve, which will start an API on your local machine.
If you have models preinstalled, they’ll be used by our extension. Otherwise, it is pretty easy to install them.
This is the way to do it, as using the ChatGPT API or any other online LLM model would require not only an Internet connection, but it also wouldn’t be private.
When it comes to choosing a model, we should consider two things:
- Efficiency of the model (how fast it responds).
- Quality of the output (or its specialization).
Autocomplete requires a very fast response from the model. Not only that, but it should also be trained specifically for code completion.
When it comes to general questions and answering in chat form, the model might be slower, but it must provide better-quality answers.
Thus, it is a good idea to stick to the default models used by the extension I will be using (which you can change later in the config file). These are:
llama3.1:8b(4.9 GB) for chat.qwen2.5-coder:1.5b-base(986 MB) for code completion.
Setup
The first thing we’ll need is some kind of extension to fetch completions from Ollama and suggest them in our development environment.
I decided to go with Continue. After installing it, you can see it in the list of extensions on the left side of your screen.
The next step is installing a model for autocomplete. You can find all available models here.
1
2
$ ollama pull llama3.1:8b
$ ollama pull qwen2.5-coder:1.5b-base
After this step, you should be able to see the models in your list on the left side of your screen. You can switch between them by clicking on the dropdown menu next to the model name.
I would recommend adding at least one model via an API key, though. This way, you actually control what you send to it, compared to the autocomplete feature. It might also be useful if you have an Internet connection and the code you are working with is not a big privacy concern.
Restart the editor, and you should see autocomplete suggestions for your code as you type. You can also select a part of your code and ask the LLM about it directly in the chat.
P.S.: after some time, I’ve decided to also add free Mistral API to the chat models. It is important not to add it as autocomplete, though. I would say Llama is pretty neat solution, and works absolutely fine. The only reason to install Mistral alongside with Llama was the fact that sometimes I might need faster results while working with non-confidential information and being connected to the Internet. However, again, local Llama works absolutely fine and is enough, in my opinion.